Super resolution의 초기 논문인 Image Super-Resolution Using Deep Convolutional Networks 논문 리뷰를 하겠습니다.
Introduction
Super Resolution (SR)은 저해상도 이미지를 고해상도 이미지로 복원하는 것입니다.
Single image super resolution (SISR)과 Multiple image super resolution (MISR)로 분야가 나뉘어져 있습니다.
본 논문에서 기존의 Sparse Coding (SC), Example-based 기법에서 더 나아가 딥러닝 기법을 적용한 기법을 제안합니다.
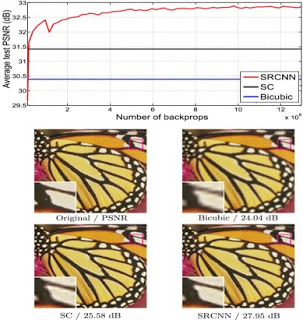
성능은 그림 1과 같습니다.
기존 기법에 비해 PSNR이 높은 것을 볼 수 있습니다.
여기서 Peak signal-to-noise ratio(PSNR)이란?
영상의 손실 압축에서 화질 손실 정보를 평가할 때 사용하는 평가지표입니다.
본 논문에서 어필하는 Contributions는 다음과 같습니다.
- 전처리가 거의 없이 데이터와 CNN을 이용하여 end-to-end SR을 함
- 전통적인 기법과 딥러닝의 상관관계를 분석하여 네트워크 구조 설계 지침
- 딥러닝 기반의 기술을 통해 높은 성능과 속도를 제공
Related Work
Image Super-Resolution
SISR 알고리즘은 4가지로 분류 가능합니다.
- Prediction models
- Edge based methods
- Image statistical method
- Patch based methods
본 논문에선 Patch based methods에 관한 설명을 간단하게 합니다.
- 저해상도와 고해상도의 쌍으로된 patch 정보(딕셔너리)를 가지고 있음
- 저해상도에서 고해상도로 복원시 nearest neighbor(NN)으로 보간
전통적인 SR 알고리즘은 grayscale이나 single channel image를 중점으로 연구
컬러 이미지는 YUV로 변환 후 Y값만 사용
이전 연구에서 컬러값을 결과 이미지에 덮어 씌운 경우는 있으나, 각 채널간 분석은 없음
Convolutional Neural Network (CNN)
CNN은 최근 이미지 분류 분야에서 성공적인 성능을 보이는 추세입니다.
객체 인식, 얼굴 인식 등 컴퓨터 비전 영역에도 접목 중입니다.
CNN이 성공하려면 몇가지 factor가 필요합니다.
- 강력한 GPU로 효과적인 학습
- ReLu를 이용 (빠른 수렴)
- 데이터 셋 접근성 용이 (ImageNet)
Deep Learning for Image Restoration
Fully connected layer (FC) 로만 이루어진 Multi Layer Perceptron (MLP) 모델, CNN으로 이미지 denoising 연구가 있었습니다.
패턴(먼지/비내림)을 제거하는 연구가 있었습니다.
위 연구들의 한계는 denoising만을 하는 점, end-to-end가 아닌 점입니다.
SRCNN
SRCNN은 그림 2와 같이 구성되어 있습니다.
bicubic interpolation으로 upscaling한 Low resolution image data를 이용합니다.
Y는 보간된 이미지, F(Y)의 방식을 통해 고해상도 X를 얻어내는 것이 목표입니다.
F는 3가지 과정으로 구성됩니다.
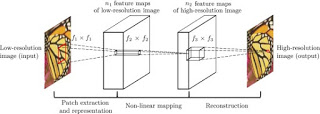
- Patch extraction and representation - Y를 overlapping하며 high dimensional vector로 변환. 즉, feature map 생성
- Non-linear mapping - 고차원 to 고차원으로 비선형 매핑
- Reconstruction - 비선형 매핑이 진행된 feature map을 통하여 X 생성
Patch Extraction and Representation
- 유명한 patch extraction기법은 PCA, DCT, Haar과 같은 선행 학습된 기법을 이용하는 것
- 본 논문에선 patch extraction을 아래 수식과 같이 정의
- W는 weight, B는 bias
- 1번째 layer에서 ReLu를 activation function으로 사용하였기 때문에 아래 수식이 도출됨
- Filter가 c X f1 X f1 인것으로 보아 channel first인 것으로 확인
F1(Y) = max(0, W1 * Y + B1)
Non-Linear Mapping
1번째 layer에서 출력된 feature map을 입력함
F2(Y) = max(0, W2 * F1(Y) + B2)
Reconstruction
- 1번째 layer와 2번째 layer간 비선형 매핑 연산에서 출력된 n1-dimensional feature를 입력함
- Activation function으로 linear를 사용함
- Loss function = Mean Squared Error(MSE)
Experiments
그림 3과 같이 1번째 layer에서 엣지를 추출하는 것이 시각화되고, 2번째 layer에서 density를 추출함

성능 실험은 filter 개수, 크기, layer 수를 변경하여 실험
Filter 개수가 많을수록 성능이 좋지만 속도는 느림
Filter 크기가 클 수록 성능이 좋음
Layer 수가 많으면 오히려 성능이 낮음


'인공지능 > 논문리뷰' 카테고리의 다른 글
| Personlab 논문 리뷰 (0) | 2021.03.15 |
|---|---|
| Pose Estimation (0) | 2021.03.15 |