강화(Reinforcement)는 시행착오(Trial and Error)를 통해 학습하는 방법 중 하나를 의미합니다. 이러한 강화를 바탕으로 강화학습은 실수와 보상을 통해 학습을 하여 목표를 찾아가는 알고리즘입니다. 기존의 신경망들이 라벨(정답)이 있는 데이터를 통해서 가중치와 편향을 학습하는 것과 비슷하게 보상(Reward)이라는 개념을 사용하여 가중치와 편향을 학습하는 것입니다. 목적은 최적의 행동양식 또는 정책을 학습하는 것입니다.
종류
- Model-Based Algorithm
- 해당 알고리즘은 환경(Environment)에 대한 모든 설명(Description)을 알고 문제를 푸는 방법입니다.
- 핵심은 직접 행동을 하지 않고, 최적의 솔루션을 찾을 수 있다는 점 입니다.
- 모델은 상태(State)와 행동(Action)을 받아서 다음 상태와 보상을 예측합니다.
- 모델은 Planning에 사용되며, 경험 전에 가능한 미래 상황을 고려하여 행동을 예측합니다.
- 모델과 Planning을 사용하여 해결하는 방식을 Model-Based라고 합니다.
- Model-Free Algorithm
- 해당 알고리즘은 Model-Based와 달리 환경(Environment)을 모르는 상태에서 직접 수행하는 방식입니다.
- 에이전트(Agent)가 행동을 통해 보상 합의 기대값을 최대로 하는 Policy Function을 찾는 것입니다.
- 환경에 대해 알지 못하고, 다음의 상태와 보상을 수동적으로 행동하여 얻습니다.
- 환경 파악을 위해서 탐사(Exploration)을 합니다.
- 탐사는 시행착오(Trial and Error)를 통해서 Policy Function을 점차적으로 학습시킵니다.
강화학습이 해결 가능한 문제
강화학습은 결정을 순차적으로 내려야 하는 문제에 적용을 합니다. 순차적으로 내려야 하는 문제를 정의하기 위해서는 MDP(Markov Decision Process)를 사용합니다.
문제를 푸는 과정은 아래와 같은 순서로 풀게 됩니다.
- 순차적 행동 문제를 MDP로 전환합니다.
- 가치함수를 벨만 방정식으로 반복적 계산합니다.
- 최적 가치함수와 최적 정책을 찾습니다.
MP(Markov Process, Chain) : MP는 이산 시간이 진행함에 따라 상태가 확률적으로 변화하는 과정을 의미합니다. 시간 간격이 이산적이고 현재의 상태가 이전 상태에 영향을 받는 확률 과정입니다. 이것을 기초로하여 MDP가 정의됩니다.
MDP(Markov Decision Process)

- 상태(State) : 정적인 요소 + 동적인 요소를 의미합니다.
- 행동(Action) : 어떠한 상태에서 취할 수 있는 행동을 의미합니다.
- Stochastic transition model : 어떤 상태에서 특정 행동을 하여 다음 상태에 도달할 확률
- 보상(Reward) : Agent가 학습할 수 있는 유일한 정보를 의미합니다. 어떤 상태에서 행동을 하여 다음 상태가 되고, 이때 받는 보상값은 다음 상태가 되는 것에 대한 보상입니다.
- 정책(Policy) : 순차적 행동 결정 문제(MDP)에서 구해야할 답을 의미합니다. 모든 상태에 대해 Agent가 어떠한 Action을 해야 하는지 정해놓은 것을 의미합니다.
- 목표는 최적의 정책(Optimal Policy)을 찾는 것입니다.
가치함수(Value Function)

순차적인 결정 문제(Sequential Decision Problem, MDP)을 풀기 위해서는 가치함수(Value Function)을 정의해야합니다. 가치함수는 현재 상태의 정책을 따라갔을 때 얻는 예측 보상의 총 합을 의미합니다. 이때 현재 보상의 추세인 감가율을 고려하여 미래 보상을 예측합니다. 에이전트는 가치함수를 통해서 보상의 합을 최대로 한다는 목표에 얼마나 다가갔는지를 판단합니다. 가치함수에 대한 방정식은 벨만 방정식(The Bellman Equation)입니다.
벨만 방정식(The Bellman Equation)

위의 그림을 보시면, 벨만 방정식을 사용하여 각각 상태에 대한 가치함수 기대값을 얻을 수 있습니다. 이것들을 모두 계산하여 최적의 정책을 찾는 것입니다.
벨만 방정식은 현재 상태와 다음 상태의 관계를 나타내는 방정식입니다. 두가지 종류가 존재합니다.
- 벨만 기대 방정식 : 반복적으로 기대값을 업데이트하기 위해서, 현재와 다음의 가치함수 사이 관계를 정의합니다. 특정 정책일 때의 가치함수 사이의 관계를 의미합니다. 모든 상태에 대한 가치함수를 반복적으로 업데이트하여 참 가치함수값이 나옵니다. 현 정책에 대한 수렴값을 구할 수 있습니다.
- 벨만 최적 방정식 : 가장 큰 가치함수를 구하는 정책을 최적 정책이라고 합니다. 벨만 기대 방정식에 맞춰 더 좋은 정책을 찾아내면 해당 정책이 바로 최적의 정책입니다. 이때, 최적의 가치함수 값을 내는 것을 최적 가치함수라고 하며, 그 때의 정책이 최적 정책입니다. 이때 가치함수들 사이의 관계식을 벨만 최적 방정식이라고 합니다.
벨만 방정식은 다이나믹 프로그래밍(Dynamic Programming, DP)으로 작은 문제들로 쪼개서 풀게 됩니다. 각 상태에서의 가치함수를 구하고 업데이트를 하고, 업데이트 이후의 가치함수를 다시 구하는 방식으로 반복합니다.
- 다이나믹 프로그래밍(DP)
- 정책 이터레이션(Policy Iteration) : 벨만 기대 방정식을 이용하여 문제를 푸는 방식입니다.
- 초기에는 무작위로 지정된 정책을 시작으로, 업데이트를 반복하여 정책을 평가(Policy Evaluation)하고, 발전해나갑니다. 이를 반복하는 방법입니다.
- 정책의 평가 방법은 가치함수를 이용하는 것인데, k번째 값을 이용하여 k+1번째 값을 업데이트 하는 방식입니다. 주변 상태들을 함께 살피고, 주변 상태의 가치함수를 사용하여 감가율을 곱하고 보상을 더해서 가능한 모든 행동에 대한 확률을 곱하고 더하는 순서로 업데이트를 진행합니다.
- 가치 이터레이션(Value Iteration) : 벨만 최적 방정식을 이용하여 문제를 푸는 방식입니다.
- 정책 이터레이션을 이용하여 최적의 가치함수를 얻을 때까지 반복하는 방식입니다.
- 정책 이터레이션(Policy Iteration) : 벨만 기대 방정식을 이용하여 문제를 푸는 방식입니다.
정책(Policy)

모든 상태에서 에이전트가 할 행동을 의미합니다. 최적의 정책은 부분 수열 상태의 기대값이 최대가 되는 정책입니다.
강화학습 워크플로는 다음과 같습니다.
강화학습을 사용한 에이전트 훈련의 일반적인 워크플로는 다음과 같은 단계를 포함합니다
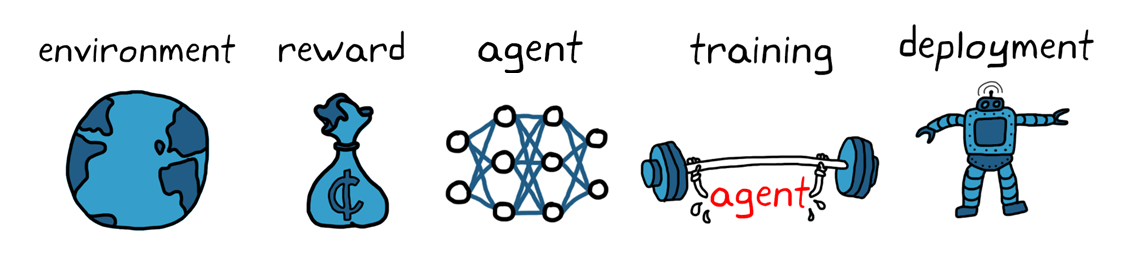
1. 환경 생성
먼저 에이전트와 환경 간 인터페이스 등의 강화학습 에이전트가 운영될 환경을 정의해야 합니다. 이 환경은 시뮬레이션 모델 또는 실제 물리적 시스템일 수 있으나 더욱 안전하고 실험이 가능한 시뮬레이션 환경이 일반적으로 더 좋은 첫 단계입니다.
2. 보상 정의
다음으로 에이전트가 성과를 작업 목표와 비교하기 위해 사용할 보상 신호 및 이 신호를 환경으로부터 계산하는 방법을 명시해야 합니다. 보상을 형성하는 것은 까다로운 작업이며 올바르게 설정하기 위해 몇 번의 시도가 필요할 수도 있습니다.
3. 에이전트 생성
그런 다음 정책과 강화학습 훈련 알고리즘으로 구성된 에이전트를 생성합니다. 그러기 위해선 다음을 완료해야 합니다.
a) 정책을 나타낼 방법 선택(신경망 또는 룩업 테이블 사용 등).
b) 적절한 훈련 알고리즘 선택. 각각의 표현 방식은 대개 각각의 특정 훈련 알고리즘의 범주와 연결되어 있습니다. 그러나 일반적으로 대부분의 최신 강화학습 알고리즘은 대규모 상태/행동 공간 및 복잡한 문제에 적합한 신경망에 의존합니다.
4. 에이전트 훈련 및 검증
훈련 옵션(중지 기준 등)을 설정하고 에이전트를 훈련해 정책을 조정합니다. 훈련이 종료된 후에는 훈련된 정책을 꼭 검증하여야 합니다. 필요에 따라 보상 신호 및 정책 아키텍처 등의 설계 선택을 다시 검토하고 재훈련합니다. 강화학습은 일반적으로 샘플 비효율적으로 알려져 있습니다. 훈련은 응용 분야에 따라 몇 분에서 며칠까지 소요됩니다. 복잡한 응용 분야의 경우 여러 CPU, GPU 및 컴퓨터 클러스터에서 훈련을 병렬 처리하여 가속할 수 있습니다.

5. 정책 배포
훈련된 정책 표현을 C/C++ 또는 CUDA 코드로 생성하여 배포합니다. 이 시점에서 정책은 독립된 의사 결정 시스템입니다.
강화학습을 사용하여 에이전트를 훈련하는 절차는 반복적인 과정입니다. 추후 단계의 결정 및 결과로 인해 학습 워크플로의 이전 단계로 다시 돌아와야 할 수 있습니다. 예를 들어 훈련 과정에서 합리적인 시간 안에 최적의 정책으로 수렴하지 않는 경우 에이전트를 재훈련하기 전에 다음과 같은 사항을 업데이트해야 할 수 있습니다.
- 훈련 설정
- 강화학습 알고리즘 구성
- 정책 표현
- 보상 신호 정의
- 행동 및 관측값 신호
- 환경 동특성
출처:https://kr.mathworks.com/discovery/reinforcement-learning.html
출처: https://davinci-ai.tistory.com/31 [DAVINCI - AI]
'인공지능' 카테고리의 다른 글
| [인공지능 서비스의 모든 것] 1. 인공지능이란? (0) | 2022.04.23 |
|---|---|
| (Tensorflow) valueerror:unknown layer : functional (0) | 2022.04.14 |
| [Keras] 자주쓰는 callback 모음 (0) | 2021.03.30 |
| Pytorch CNN-LSTM 모델 설계 (0) | 2021.03.17 |
| pytorch class weight 주는법 (0) | 2021.03.16 |






